
Imagine you’re a seasoned thief casing a high-security vault. You notice that the guards meticulously follow a timed routine: one unlocks the outer door before pausing for a security check, then another unlocks the inner vault.
In a race condition exploit, you don’t pick the locks; you exploit the gap. The split-second pause in the system is your entry point. You wedge the outer door before it fully shuts, and as the first guard moves on, assuming their job is done, you slip through the crack.
This is the essence of race condition exploitation in the digital world. Two or more processes access a shared resource, like that vault. There’s an assumption of order or sequence. If one process finishes before the other starts, everything’s secure. But if an attacker can race ahead, slip into that unguarded moment when the resource is exposed but not yet protected, they can seize control, manipulate data, or escalate privileges.
Race windows
A race window is the critical period during which a system is vulnerable to unintended behavior. This is due to the unpredictable order in which different processes or threads access shared resources. In simpler terms, it’s the window of opportunity for a race condition to occur.
A common, real-life race window scenario is the brief interval between the availability check and the completion of a purchase. This is where the outcome depends on which user’s transaction gets processed first. Race windows are often very short, sometimes just milliseconds or even less. Their duration depends on various factors, including the speed of a system, network latency, and the specific operations being performed.
Limit overrun
Limit overruns are the most popular and basic form of a race condition. These occur when a system’s intended limitations on actions are bypassed due to concurrent operations. These vulnerabilities are distinct from issues caused by insufficient rate limiting, which focuses on controlling the frequency of actions over time. For example, consider a concert ticket website that allows only one ticket per user. The site’s code might first verify that the user hasn’t already purchased a ticket before proceeding with the transaction.
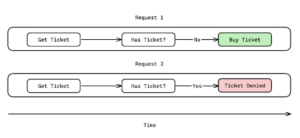
Requests are sent sequentially.
However, an attacker could potentially exploit a race condition by initiating multiple purchase requests simultaneously. If these requests manage to slip past the verification step before any of them are finalized, the attacker could end up with multiple tickets, despite the intended restriction.
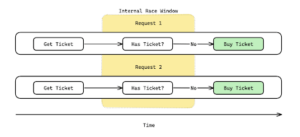
Requests are sent in parallel or rapid succession.
Single-endpoint race conditions
A single-endpoint race condition arises when multiple requests are sent concurrently to the same endpoint (e.g., a web page or an API endpoint), leading to unintended interactions and potentially exploitable behaviors.
In a single-endpoint race condition, the server’s handling of simultaneous requests can lead to a collision of states or data manipulation, where the outcome depends on the order in which requests are processed. Attackers can exploit this condition by carefully timing and crafting their requests to manipulate the application’s logic or data. This often leads to unauthorized access, data leaks, or other malicious outcomes.
To illustrate, imagine a website’s password reset functionality works as follows:
- User initiates reset—A user enters their username and requests a password reset.
- Session storage—The server generates a unique reset token and stores it in the user’s session along with their username.
- Email sent—An email is sent to the user’s address with a link containing the reset token.
- Token verification—When the user clicks the link, the server verifies the token in the session to ensure it’s valid. After confirming validity, it allows the user to change their password.
The problem arises when two password reset requests are sent almost simultaneously from the same browser session (which shares the same session ID) but for different usernames (e.g., “attacker” and “victim”). Here’s how that problem happens:
- First request—The server receives a request to reset the password for “attacker.” It stores “attacker” and a new reset token in the session associated with the session ID.
- Second request—Before the server finishes processing the first request, another request arrives to reset the password for “victim.” Because this request comes from the same browser session (using the same session ID), the server overwrites the stored username in the session with “victim” and generates a new reset token.
As a result, the session now incorrectly contains “victim” as the username but the reset token that was originally intended for “attacker.” This happens because the session data, identified by the session ID, is overwritten with each new request within that session.
The attacker can now use the reset link sent to the “victim’s” email. Since the token in the session matches the one in the link, the server mistakenly believes the attacker is the “victim” and allows them to change the “victim’s” password.
Multi-endpoint race conditions
Multi-endpoint race conditions are another type of race condition that occurs when multiple endpoints (or interfaces) within a system interact with the same data or resource concurrently. These endpoints could be different web pages, API endpoints, or even functions within the same application.
Unlike traditional race conditions that often involve competing actions within a single process or request, multi-endpoint race conditions involve interactions between different components of a system. This can make them more difficult to identify and exploit, as the vulnerability might not be evident from analyzing a single endpoint in isolation.
To illustrate, consider an online store with a variety of products, a shopping cart, and a checkout process that deducts the purchase amount from a customer’s account. A malicious actor could exploit this setup by strategically adding an item to their cart after initiating the checkout process and after the system verifies that sufficient funds are available in the customer’s account. This manipulation essentially circumvents the financial check, allowing the attacker to acquire the additional item at an unintended price. The diagram below demonstrates how “Request 2” (adding another item to the cart) can exploit this substate. If “Request 2” is processed during this window of vulnerability, it can modify the cart’s contents before the checkout process in “Request 1” has finalized the purchase based on the initial cart state. This discrepancy can lead to issues like incorrect billing or unauthorized purchases.
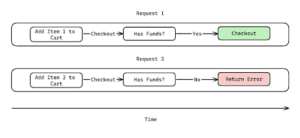
Intended application flow.
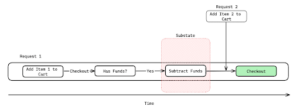
A multi-endpoint race condition—adding an item before the checkout process is completed.
You can replicate this same exploit by trying it in Portswigger’s race condition lab HERE.
Challenges
The primary challenge in successfully exploiting race conditions lies in ensuring that multiple requests are processed simultaneously, with minimal discrepancies in their processing times (ideally, under 1–5 ms). However, there are some issues when it comes to achieving this:
- Network jitter—The variability in latency or delay in data transmission over a network. This can cause unpredictable fluctuations in the arrival times of simultaneous requests. This makes it difficult for attackers to precisely time their actions to exploit the race condition.
- Internal latency—The target system’s servers or applications can also introduce timing variations. Even if an attacker sends perfectly timed requests, internal processing delays can disrupt the order in which requests are handled. This hinders the successful exploitation of the race condition.
To overcome this challenge, we can leverage specific techniques tailored for synchronizing these requests depending on the HTTP version used:
- For HTTP/1.1 requests—Last-byte synchronization involves sending multiple requests with most of their data upfront, leaving the transmission of a small final fragment of each request for later, which is then sent together to achieve simultaneous requests at the server.
- For HTTP/2 requests—Single-packet attacks involve sending multiple requests over a single TCP connection. This reduces network jitter and ensures simultaneous arrival at the server. This technique, in conjunction with the carefully timed transmission of final request fragments, enables us to hit the narrow race window more consistently and effectively.
By sending a large amount of requests simultaneously, we can also mitigate the effects of internal latency, ensuring a higher chance of successful attack.
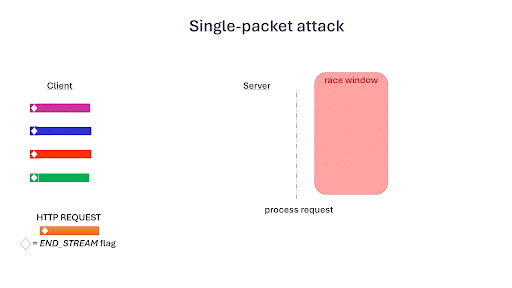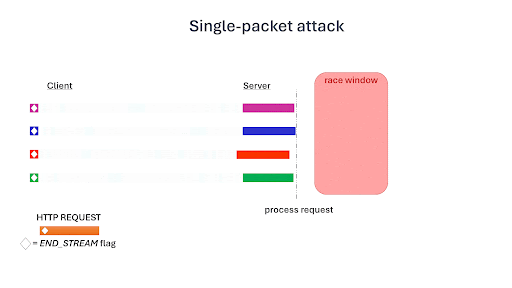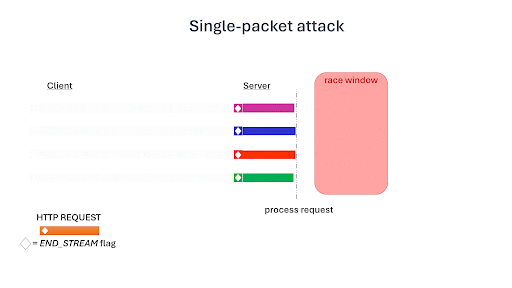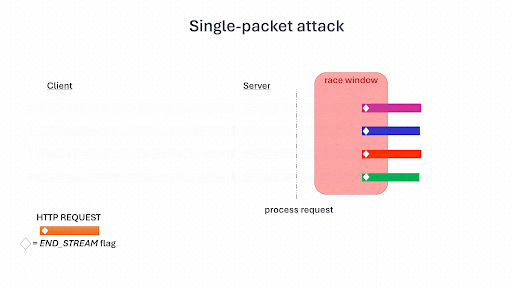
GIF taken from: https://blog.adriapt.xyz/posts/SinglePacketAttack/
Connection warming
Even with the packet synchronization techniques, lining up the race window for each request may still be difficult due to internal latency, especially when dealing with multi-endpoint race conditions. Hence, the concept of “warming up” a connection was introduced. Connection warming involves sending dummy requests to a server beforehand, establishing connections and potentially pre-loading resources. This helps normalize request timing by minimizing the overhead of connection establishment and initial resource allocation for subsequent requests. By ensuring that a server is “warmed up” and connections are already active, an attacker can reduce the variability in processing times, increasing the likelihood of simultaneous request handling and maximizing the chances of triggering the race condition.
Overcoming rate or resource limits
If connection warming doesn’t work, we can still manipulate timing by exploiting a server’s rate or resource limits. Burp Intruder can introduce client-side delays, but this can be unreliable on high-jitter networks due to the split packets.
Instead, we can leverage a common security feature in applications by manipulating servers because they often delay requests when overwhelmed. By intentionally triggering rate or resource limits with dummy requests, we create a server-side delay that allows us to effectively use the single-packet attack, even when delayed execution is necessary.
Conclusion
Much of the information provided is sourced from the references listed below. If you have further questions, be sure to explore these references and try out the labs offered by PortSwigger for hands-on experience.


